![]()
1.8. N-gram og galakser#
Data kan hentes ut fra NB N-gram ved hjelp av klassen Ngram.
Ngram tar følgende parametre:
Ngram( words=[ "han", "hun" ], from_year=1950, to_year=1990, doctype="bok" )
Ngram-obektetet inneholder en dataramme som kan analyseres, og metoder for visualisering og analyse.
Vi støtter N-gram basert på bøker eller aviser. Man kan velge hvilket korpus man vil bruke med å sette paramenteret doctype til "bok" eller "avis". Hvis ingen blir spesifisert brukes bokkorpuset.
import dhlab as dh
from dhlab import Ngram, NgramBook, NgramNews
from dhlab.ngram.nb_ngram import nb_ngram
from dhlab.api.nb_ngram_api import make_word_graph
from dhlab import graph_networkx_louvain as gnl
Ngram
NgramBook
NgramNews
nb_ngram
make_word_graph
clustre
1.8.1. Plotting#
# Ngram på 'han' og 'hun' på bøker utgitt 1950-1990
Ngram(
words=[
"han",
"hun"
],
from_year=1950,
to_year=1990,
doctype="bok"
)
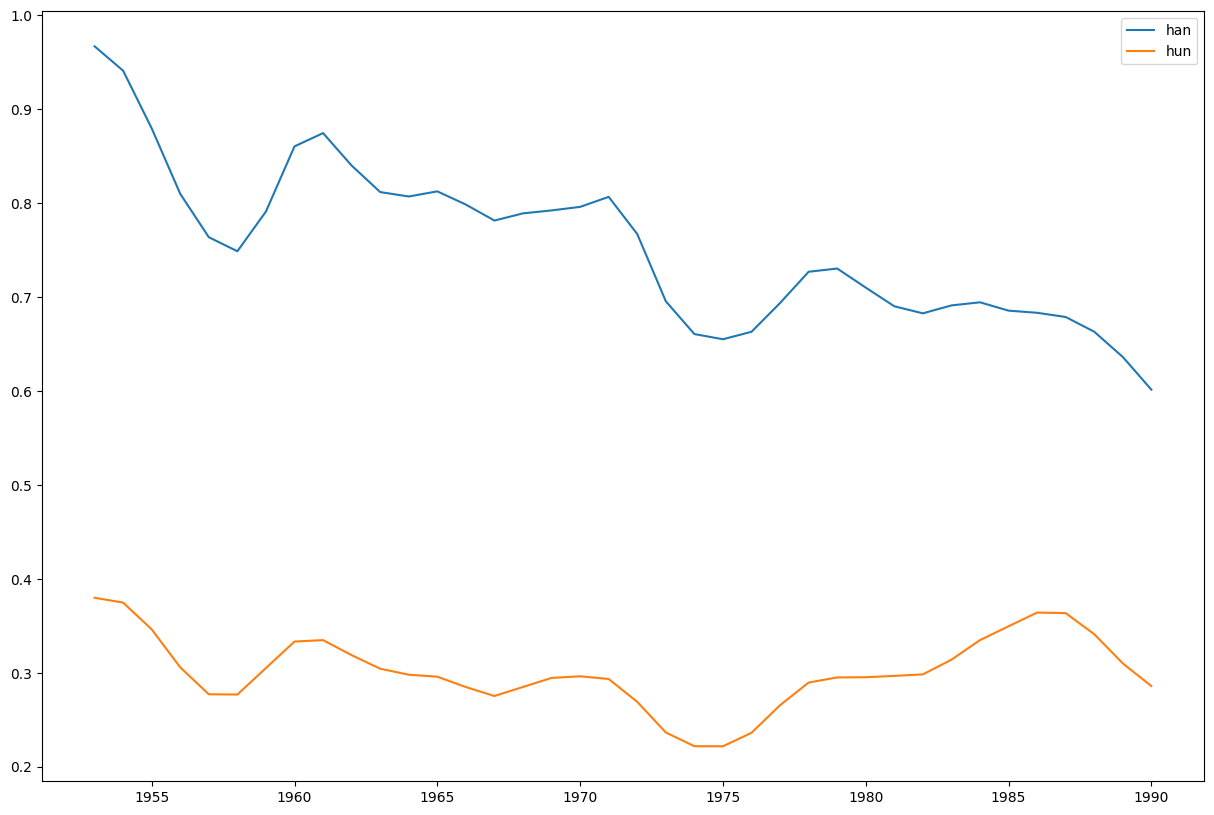
Visualisering kan konfigurerers med Ngram.plot()
Ngram.plothar paramenteretsmoothi tillegg til paramenterene tilpandas.DataFrame.plot().smoother et parameter for glatting. Forekomsten av et ord er til en viss grad styrt av tilfeldigheter, for eks. hvilke bøker som ble utgitt ett bestemt år: For å rette noe på denne skjevheten, «glattes» resultatene ut før de vises. Glatting vil si at relativfrekvensen for ett år beregnes som et gjennomsnitt av frekvensen i dette og et visst antall forutgående og etterfølgende år: En glatting på fire innebærer at resultatene for fire år før og fire år etter legges sammen med dem for det aktuelle året, delt på ni (antall år totalt). Dette gjør kurvene jevnere enn i rådataene hvor det er langt mer spisse topper.
# Ngram på 'han' og 'hun' på bøker utgitt 1950-1990
# Glatting, plot-type, størrelse og strektykkelse
Ngram(
words=[
"han",
"hun"
],
from_year=1950,
to_year=1990,
doctype="bok"
).plot(smooth=10, kind="line", figsize=(8, 4), lw=4)
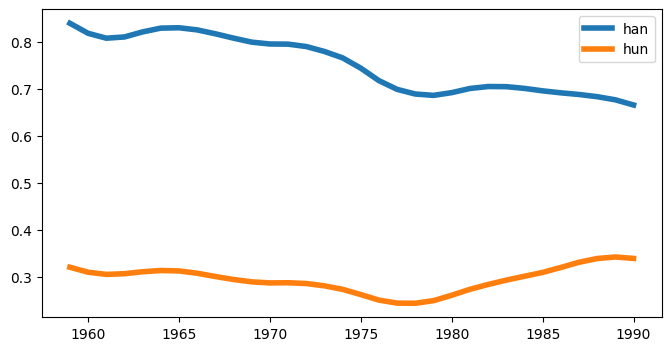
1.8.1.1. Dataramme#
# Adgang til N-grammet som dataramme gjennom Ngram.frame
Ngram(
words=[
"han",
"hun"
],
from_year=1950,
to_year=1990,
doctype="bok"
).frame.head()
| han | hun | |
|---|---|---|
| 1950 | 0.961575 | 0.376442 |
| 1951 | 0.990294 | 0.370878 |
| 1952 | 0.946277 | 0.390889 |
| 1953 | 0.965377 | 0.377961 |
| 1954 | 0.803514 | 0.321345 |
1.8.1.2. Avis N-gram#
Lag N-gram basert på avis ved å sette doctype til "avis".
Ngram(
["det", "der"],
doctype="avis",
from_year=1810,
to_year=2010
).plot(smooth=10, figsize=(10, 5), lw=5)
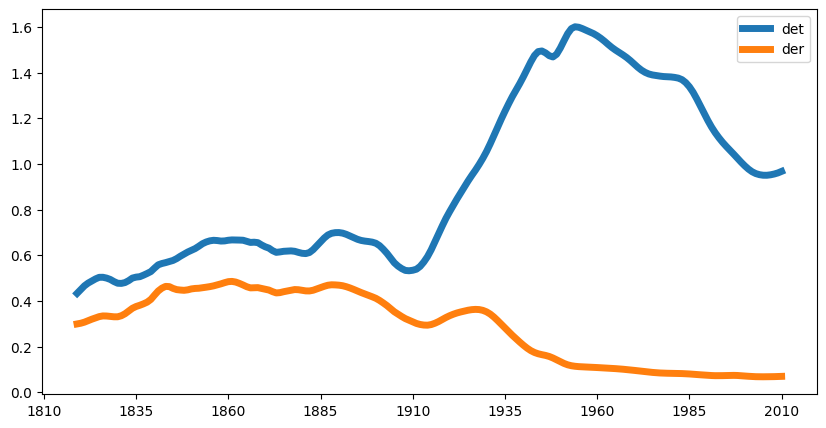
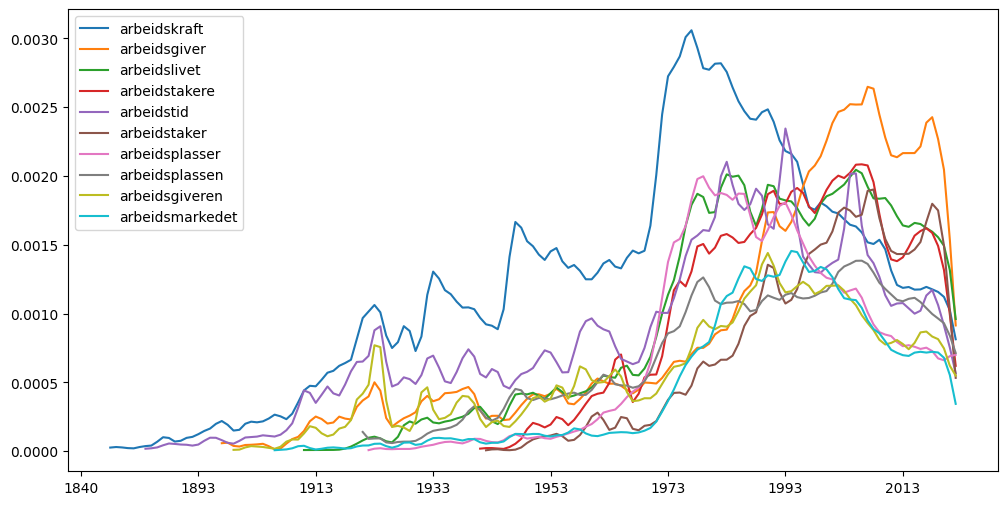
1.8.2. N-gram med jokertegn#
Ngram(
["arbeids*"],
from_year=1810
).plot(figsize=(12, 6))
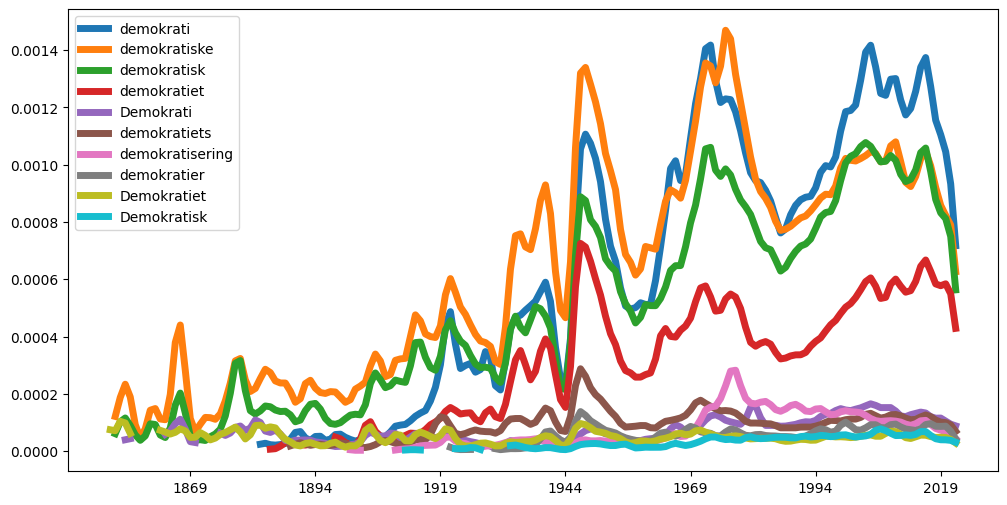
Ngram(
["demokrati*"],
from_year=1800
).plot(smooth=4, figsize=(12,6), lw=5)
1.8.3. Galakser#
Galaksene måler koblinger mellom ord, og kan brukes for å lage sett av ord til forskjellige formål, som for eksempel sentimentanalyse, eller stedsnavn.
is_graf = make_word_graph("is", corpus='all', cutoff=16, leaves=0)
Grafer tegnes og analyseres med pakken networkx. Kommandoer er bygd over den pakken, og kommando for å vise grafen er show_graph fra modulen graph_networkx_louvain.
gnl.show_graph(is_graf, spread=5)
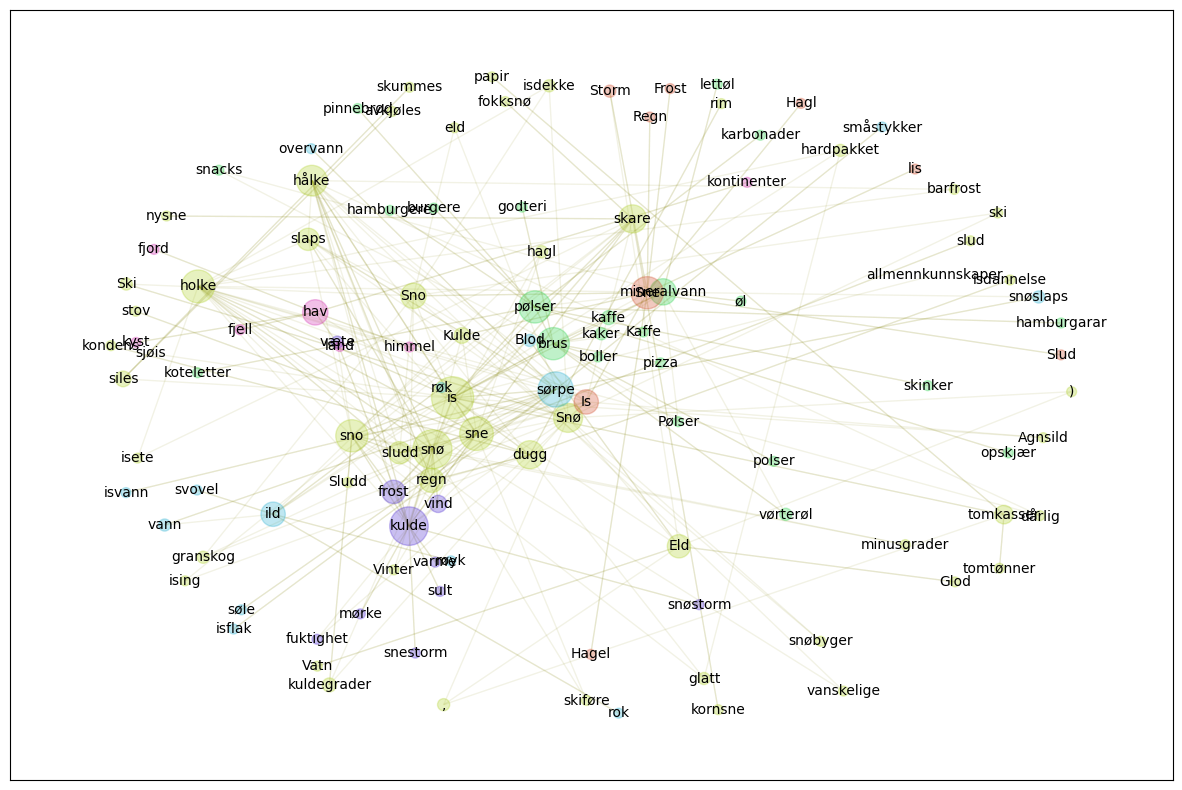
Bruk kommando show_communities fra gnl for å se på clustre.
gnl.show_community(is_graf)
1 Vatn, is, Ski, skiføre, nysne, slud, kondens, slaps, sno, snøbyger, barfrost, Sno, hagl, snø, fokksnø, Agnsild, isete, dugg, ski, ), dårlig, isdekke, holke, eld, ,, isdannelse, Vinter, glatt, kuldegrader, skare, papir, sludd, avkjøles, hålke, stov, sjøis, Kulde, hardpakket, regn, Eld, granskog, Sludd, ising, tomtønner, vanskelige, skummes, tomkasser, rim, siles, minusgrader, Snø, Glod, sne, kornsne, allmennkunnskaper
2 snacks, lettøl, Kaffe, brus, mineralvann, karbonader, burgere, skinker, koteletter, øl, boller, pølser, opskjær, godteri, hamburgarar, kaker, vørterøl, pizza, pinnebrød, Pølser, polser, hamburgere, kaffe
3 isflak, overvann, søle, røyk, ild, småstykker, røk, isvann, sørpe, vann, rok, Blod, snøslaps, svovel
4 kulde, snøstorm, fuktighet, frost, varme, væte, vind, snestorm, mørke, sult
5 hav, kyst, land, fjord, fjell, himmel, kontinenter
6 Sne, Frost, lis, Storm, Hagl, Is, Slud, Regn, Hagel
True